Low-code vs. High-code Data Pipelines

In the hybrid scenarios that I recently mentioned in my post about the Data Lakehouse and that still dominate the industry, Spark machines are often used in many places to perform data transformations. In this context, Spark has almost become the standard as an open source system with highly efficient distributed data processing.
However, Spark alone is initially a hurdle to overcome, even for experienced developers. In addition, there is time-consuming optimization work when working with complex Python workflows, for example. The developer has to become active themselves in many places in order to get the best possible out of it and save costs. This brings with it a dilemma that has been attempted to be solved in the past with various approaches.
A central question that companies often ask themselves is how they can quickly implement redundant processes by simple means. They do not want to become too dependent on expensive specialists. So the goal is to get to the solution quickly and to make it reasonably easy for non-specialists to operate. Low personnel and development costs vs. higher operating expenses.
 Initial cost often equals the tip of an iceberg, Image source:
Pixabay
Initial cost often equals the tip of an iceberg, Image source:
Pixabay
Low-code - The Easy Way
The most common approach to achieving this goal is to rely on low-code platforms. These are platforms that offer simple, commonly used functionality in a simple, quick-to-learn user interface. These are persisted under the hood as configurations in common formats such as JSON, YAML or XML, ultimately executed programmatically by an interpreter.
As with programming, for example, copy operations, loops and evaluation activities are offered, which can be assembled by a user via a graphical editor as building blocks that can be clicked together. This function package is usually extended by connectors that integrate APIs from well-known third- party providers.
The advantage is that it becomes possible even for an unskilled data engineer to implement simple use cases. Furthermore, the data pipelines become mostly self-documenting and can be designed much faster by the user without using code. Coupled with managed resources provided by many cloud providers, this can abstract away the need to own infrastructure.
One disadvantage, however, is that inexperienced data engineers usually end up with less optimized solutions using low-code. These may get the job done but generate very high operating expenses over a long period. Further problems arise from depending on the particular vendor unless it is an open-source platform running on its own resources. This also makes future migration to other systems more costly.
Complex use cases will also be less easy to implement. From my experience, I claim that about 80% of use cases can be implemented with low-code. However, it takes about 80% of the total development time to implement the remaining more complex use cases. Pareto distribution.
Some low-code platforms offer certain hybrids for this, for example Mapping Data Flows, which you know from Azure Data Factory. These are more complex data pipeline jobs that can be created and executed based on Apache Spark clusters, which are provided by Microsoft. This also enables larger transformations for real ETL, but only to a certain extent.
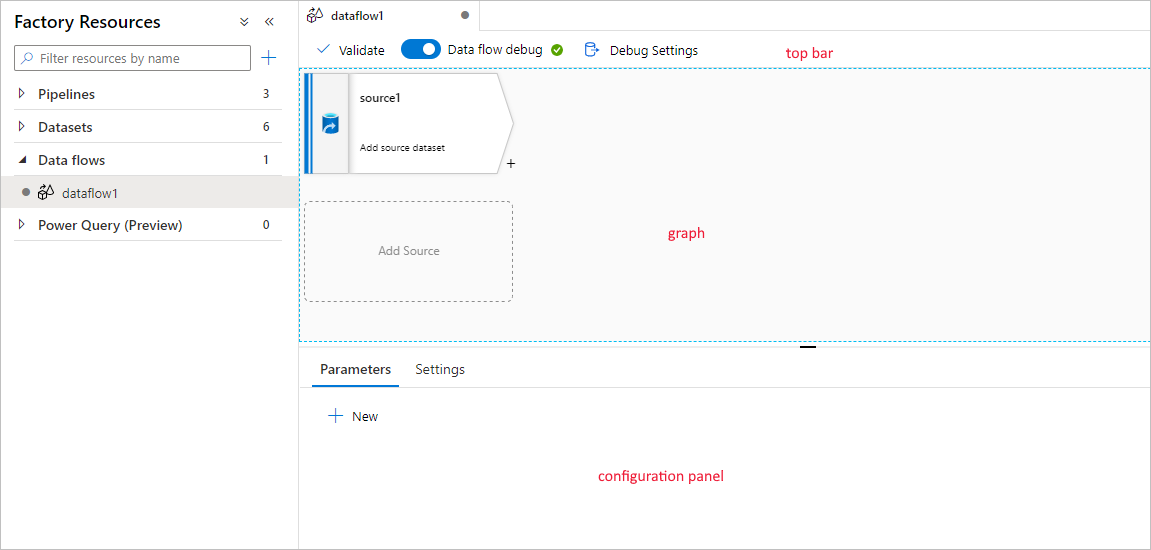 Build ETL pipeines in a browser with Data Factory, Image source:
Microsoft
Build ETL pipeines in a browser with Data Factory, Image source:
Microsoft
Many companies will therefore still have to rely on other third-party providers that enable the external execution of complex code. Using Azure Data Factory as an example above, HDInsight or Databricks, for example, provide this capability, but Azure Functions can also be used for this purpose. In Azure Synapse Analytics, there is at least the possibility to execute code on on-demand clusters with so-called notebooks. The same applies to comparable solutions in AWS or Google Cloud.
So the problem becomes visible: In order to map all use cases, you cannot get around a mix of different frameworks. And this overhead leads to teams having to familiarize themselves with different technologies. Sometimes, certain hurdles also arise, because inexperienced engineers are not in a position to implement or even maintain complex use cases. Experienced engineers would like to implement simple use cases in an elaborate but optimized way.
High-code - Expensive but Efficient
So the question is, why not go directly to high-code? By this I mean raw, self-managed and executed code. For example, Python programs running on their own virtual machines (hosted in the cloud) or on a Kubernetes cluster.
As mentioned earlier, this would require 80% of use cases to be implemented as code. If these are jobs that don’t run very often and aren’t expected to have huge operating costs, then development costs could grow a lot. If long-lived pipelines are required, then the development costs can be amortized in the long term.
It is also possible with high-code to create very optimized and simplified frameworks. These can also be used by less experienced forces by incorporating them. Examples of existing open source solutions are Bonobo or petl for Python.
 Write data pipelines in high-code with Bonobo, Image source:
Bonobo
Write data pipelines in high-code with Bonobo, Image source:
Bonobo
Good developer teams are, however, also able to develop such frameworks for the respective requirements. Thus, one would have a uniform platform, which makes both easy and complex data pipelines fast manufacturable. Just not with a pretty graphical editor.
However, it makes sense to diversify into different solutions. After all, high-code doesn’t develop. And programming languages also change and improve. Open source packages can become obsolete and security holes can appear. Experienced engineers are often scarce and above reasons make a company dependent on experienced personnel.
So, compared to many benefits you automatically get with low-code mixed platforms, the initial effort is higher. It’s like building a house: Do I want a good, long-lasting foundation or do I want to adapt my house often to changing requirements?
Conclusion
In the end, it is a question of how much you want to invest in the initial development. If you want to get to the solution quickly and don’t want to invest too much in the initial development, then low-code is the way to go. However, you should be aware that you will have to invest more in the long term.
Especially, when building critical data pipelines that are expected to run for a long time, it is advisable to invest in high-code. This will save you a lot of money in the long term and reduce the need for extensive and reoccurring maintenance work. Yet, it might be difficult to find experienced engineers to implement the solution.
Choosing the right solution is not always easy. But if you analyze the requirements and priorities of your company, you will find the right solution for you. If unsure, you can always start with low-code and then partially migrate to high-code if necessary. Last but not least, you can also use a mix of both approaches. In this post, I introduce with Delta Live Tables a hybrid solution that combines the best of both worlds.
If you have any questions or feedback, feel free to write me a mail or reach out to me on any of my social media channels.