Data Lakehouse as Single Source of Truth

Over the past few years, the data lake architecture has become the de facto standard for big data use cases. However, many companies still found their data layer on relational databases for BI use cases. This was also the case for one of my previous projects. There, we had a data warehouse for BI use cases and a data lake for data scientists.
In order to break this redundancy, we sought to move to the Data Lakehouse architecture, which was developed exactly to address these issues. This new approach to data engineering unifies data lake and data warehouse and addresses the shortcomings of the data lake architecture.
Delta Lake
In this particular project, we mainly worked with Azure Data Factory and Azure Databricks. One of the main selling points of Databricks is its outstanding support for Delta Lake. This open source architecture, unlike database management systems, is based on bare files, delta tables, to be exact.
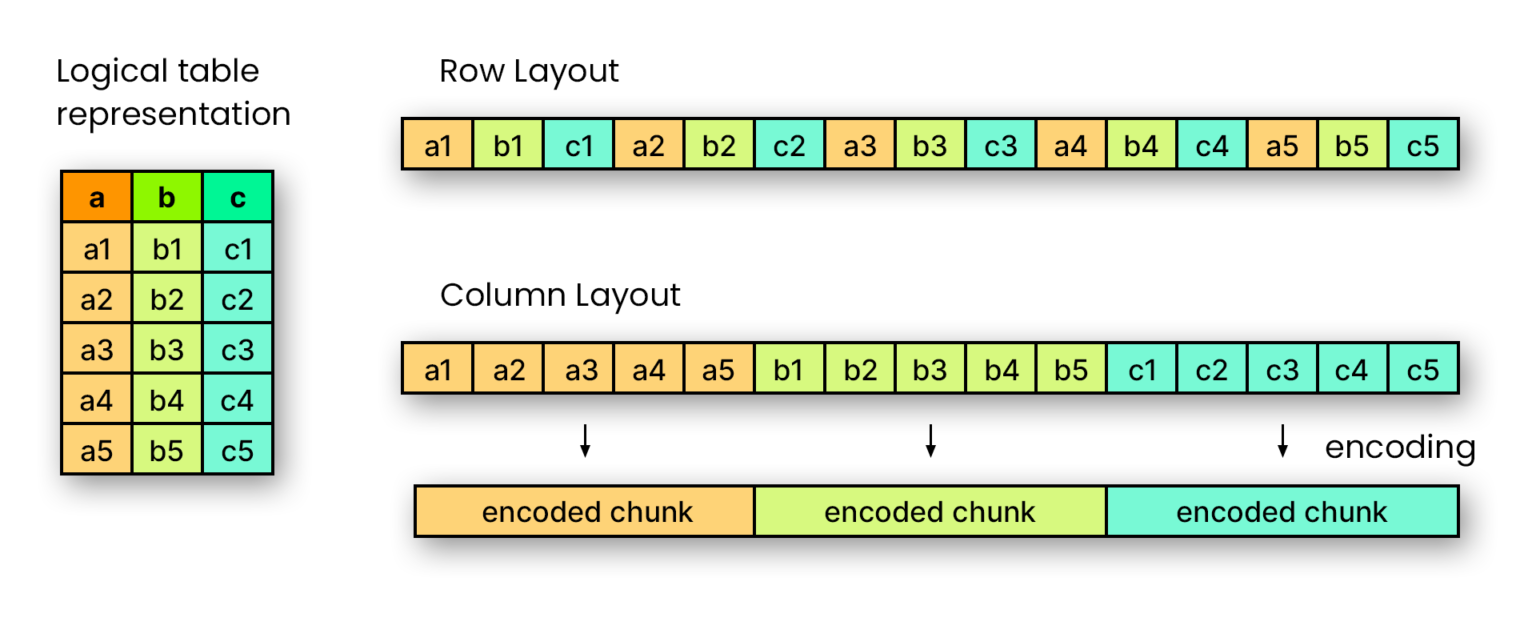
First, delta tables extend the popular file format Apache Parquet. This, in turn, is a column-oriented data file format designed for efficient data storage and retrieval. You can think of it this way: in a Parquet file, each column is stored as a contiguous unit, one after the other. This is in contrast to row-based formats, such as CSV or JSON.
 Row-based vs. Column-based Representation, Image source:
Dremio
Row-based vs. Column-based Representation, Image source:
Dremio
More precisely, a Parquet file is divided into so-called Row Groups. These represent a logical, horizontal partitioning of the data in rows. Each Row Group contains a Column Chunk, i.e. a part of the data for a specific column. This is guaranteed to be contiguous, which simplifies reading data sets with significantly more rows than columns. Last, the Column Chunks are once again divided into several Pages, which are indivisible regarding compression and encoding.
Apache Parquet was created in collaboration released by Twitter and Cloudera in 2013 as an open source format, which is independent of any programming language. The goal was to develop a state-of-the-art columnar storage layer that can be used by existing Hadoop frameworks.
Since all values in a given column have the same type, compression works better, and we can apply it in a type-specific manner. In addition, column values are stored continuously, so a query engine can skip loading columns that are not needed. This makes the Parquet format very efficient for OLAP (online analytical processing) use cases where we need to ensure a fast response to multidimensional analytical queries.
However, along with this comes a weakness of the Parquet format: due to its column-oriented storage approach, Apache Parquet is not very well suited for data insertion and deletion transactions. Ideally, one only adds new data without changing the existing data set. This is equally true for updating existing data. Sometimes, it is equally desirable to store different versions of the data set so that one can restore old holdings in case of emergency.
To address these issues, the open source project Delta Lake was created. Delta Lake provides ACID transactions, scalable metadata processing, and unifies streaming and batch data processing on existing Data Lakes such as S3, ADLS, GCS, and HDFS.
This is ensured by serializable isolation levels that prevent readers from seeing inconsistent data. In addition, the distributed processing power of Spark is leveraged to handle all metadata for petabyte-scale tables with billions of files. A table in Delta Lake is both a batch table and a streaming source and sink. Streaming data ingest, batch historical backfill, interactive queries - everything works out-of-the-box.
Schema mismatches are handled automatically to prevent insertion of erroneous records during ingest. And built-in data versioning enables rollbacks, full historical audit trails, and reproducible machine learning experiments. Ultimately, even merge, update, and delete operations are supported to enable complex use cases such as change data capture, Slowly Changing Dimensions (SCD) operations, streaming upserts, etc.
Cost of Storage vs. Cost of Processing
In recent decades, due to infrastructure developments, a major transformation occurred in data processing. Roughly speaking, the cost of data storage became lower and lower, while the amount of data to be processed became larger and larger.
Previous architectures such as data warehouses can no longer cope with these volumes of data, often unstructured or semi-structured, and are correspondingly expensive to operate and maintain, as well as to integrate. For this reason, it is a logical evolution to rely on an architecture that uses low-cost cloud storage, namely a data lake.
For common OLAP use cases, it makes sense to combine the aforementioned Delta Lake with a Data Lake to store data in files rather than relational databases. The problem with this, however, is that I now need several other components for my infrastructure management.
On the one hand, there is the need for resources that integrate my data from various other systems into my data lake. On the other hand, I need to provide a way for my data users to download the data they want to process.
Because of this, many companies in the past developed peculiar hybrid systems where they stored all forms of data in a data lake, but transferred parts to structured reports in data warehouses via an ETL (Extract, Transform, Load) process.
Unstructured data is provided directly to users in unstructured format via a cloud API, while structured data is provided via the data warehouse. The result: double rights management, redundant ETL workflows, multiple data transfers, differences in stored and productive data, and so on and so forth.
Data Lakehouse - An Extension
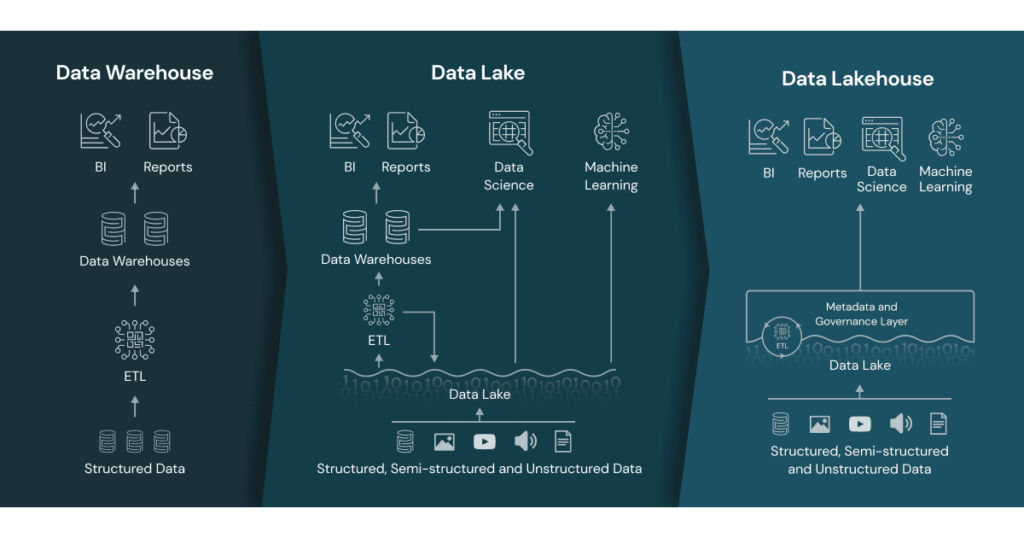
In order to unify these approaches, the concept of the Data Lakehouse was developed. This concept builds on the above and unifies redundant operations by making everything happen on the data lake.
Instead of using Spark clusters or other servers only for transforming unstructured data into structured data, as Databricks has been used for a long time, Spark clusters now become the public endpoint for downloading data.
The main part of the data is stored in delta tables on cheap storage in the cloud. But unlike in a traditional data lake, the access is regulated by a new metadata layer that manages all objects in data catalogs. This also includes rights management, as well as other data origin information for data lineage.
 The Data Lakehouse offers raw and curated data, Image source:
Databricks
The Data Lakehouse offers raw and curated data, Image source:
Databricks
The metadata layer acts as a single source of truth for all data. This is a huge advantage, because it allows you to manage all data in one place, and not in several different systems. You can add external tables from various formats, such as CSV, JSON, Parquet, and so on. Further, your curated data is stored in production-ready delta tables, which are optimized for analytical workloads. It is even possible to add tables from other cloud providers while your metadata layer acts as the sole entry point.
Like this, you can offer your end users one interface for raw and curated data unlike maintaining two separate systems as before. Data analysts can access their raw data in the same way as business users will do for curated data. Support for programmatic APIs, as Spark provides it, makes it especially easy for developers to ingest the data they need.
Like the serving layer, the processing layer works on top of cheap Spark clusters that can be managed on the same platform. This means that you can use the same infrastructure, such as a self-managed Kubernetes cluster or Databricks as analytics platform that combines all these ideas. Everything that needed separate solutions before comes together in one place.
Conclusion
The Data Lakehouse completes the idea of the delta lake, so to speak, and makes the use of data warehouses obsolete for the time being. One could even say that the Data Lakehouse represents a data warehouse, only with open- source, easily accessible formats, low-cost storage and high-performance, on- demand processing as its basis.
It offers a single source of truth for all data, and thus a single point of management. Platforms can build on top of it to make the need for redundant infrastructure obsolete. This reduces the cost for infrastructure management and allows companies to focus on their data.
In working with the architecture, I can see that the potential is huge and that the Data Lakehouse is a very promising concept. It is a logical evolution of the data lake, and it is a great way to make data available to all users in a simple and efficient way. Especially in large enterprises, I’m convinced that the digital transformation will be accelerated by the Data Lakehouse.
If you have any questions or feedback, feel free to write me a mail or reach out to me on any of my social media channels.