
Es ist nun fast ein Jahr her, dass Databricks ein neues ETL-Framework unter dem Namen Delta Live Tables veröffentlicht hat. Damit setzt das in San Francisco ansässige Unternehmen auf die Strategie, seine bestehende Datenplattform als Allzweck-Tool nutzen zu können und treibt die Transformation zu einer Single-Source-of-Truth voran.
Da ich mich bereits seit über einem Jahr mit verschiedenen Anwendungsfällen auf der Plattform beschäftige, ist dies nicht an mir vorbeigegangen. Und so hatte ich in den letzten Monaten die Gelegenheit, mich mit dem neuen ETL-Framework und verschiedenen neuen Funktionen der Plattform auseinanderzusetzen.
Warum ein anderes ETL-Framework?
Delta Live Tables basiert auf der Idee des Data Lakehouse. Dabei handelt es sich um einen Ansatz, der traditionelle Data Warehouses mit Data Lakes vereint und viele Vorteile bietet. Wenn Sie mit diesem Thema noch nicht vertraut sind, sollten Sie sich meinen früheren Beitrag ansehen, in dem ich das Konzept des Data Lakehouse ausführlicher erkläre.
Darüber hinaus ist Delta Live Tables eine Mischung aus gängigen ETL-Ansätzen. Diese werden in der Regel entweder als Low-Code oder High-Code umgesetzt. Sehen Sie sich unbedingt meinen letzten Beitrag über die Vorteile dieser Konzepte für die Datenverarbeitung an. Daraus können Sie ersehen, warum Databricks eine neue Strategie für sein ETL-Framework verfolgen könnte.
Delta Live Tables - ein Hybrid?
Pipeline-Definition
Während die meisten Low-Code-Plattformen auf eine grafische Benutzeroberfläche setzen, die vom Benutzer zusammengeklickt werden kann, setzt Delta Live Tables auf Code als Pipeline-Definition. Dieser wird durch ein mitgeliefertes Paket so vereinfacht, dass er auch von weniger erfahrenen Ingenieuren genutzt werden kann.
Derzeit werden davon die Programmiersprachen Python und SQL unterstützt. Für Python gibt es das Closed-Source-Paket dlt, das in jede Pipeline-Definition importiert werden muss.
import dlt
Ansonsten handelt es sich per Definition um ein normales Notizbuch.
Tabellen und Ansichten
In einer Delta Live Tables-Pipelinedefinition kann der Entwickler neben der Möglichkeit, Funktionen zu schreiben, nun auch Tabellen oder Views definieren. Diese sehen aus wie gewöhnliche Funktionen, sind aber mit einem Dekorator versehen.
@dlt.table
def raw_table():
return spark.read.csv("s3://my_bucket/my_table.csv")
Außerdem können Sie andere Metadaten für den Dekorator angeben und sogar den Speicherort ändern, wenn Sie nicht den Standardwert aus der Pipeline-Konfiguration verwenden wollen. Dies kann nützlich sein, wenn dieser Wert je nach Umgebung unterschiedlich sein soll.
@dlt.table(
name="meine_tabelle",
description="Dies ist meine Tabelle",
location="s3://raw/my_table"
)
def raw_table():
return spark.read.csv("s3://raw/meine_tabelle.csv")
Im obigen Beispiel wird eine Tabelle definiert, die aus einer CSV-Datei gelesen wird. Diese Tabelle wird dann ausgeführt und an dem angegebenen Ort gespeichert. Es ist jedoch auch möglich, neben solchen Batch-Jobs auch Streaming-Jobs zu definieren, die aus einem Kafka-Topic lesen, wie im folgenden Beispiel.
@dlt.table(
name="meine_tabelle",
description="Dies ist meine Tabelle",
location="s3://raw/my_table"
)
def raw_table():
return (
spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "<server:ip>")
.option("subscribe", "topic1")
.option("startingOffsets", "neueste")
.load()
)
Ein nettes und hilfreiches Feature ist auch Auto Loader, ein Tool, mit dem Databricks die Möglichkeit bietet, Verzeichnisse in der Cloud als Streaming-Quelle zu nutzen. Neue Dateien werden automatisch erkannt und in die Pipeline geladen. Ein Checkpoint-Mechanismus sorgt dafür, dass keine Dateien doppelt verarbeitet werden. Es ist aber auch möglich, alle Dateien bei Bedarf erneut zu verarbeiten.
@dlt.table(
name="meine_tabelle",
description="Dies ist meine Tabelle",
location="s3://raw/my_table"
)
def raw_table():
return (
spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.load("s3://my_bucket/my_raw_data")
)
Automatische Orchestrierung
Nachdem Sie nun einige Roh- oder Bronzetabellen definiert haben, können Sie direkt in Delta Live Tables mit ihnen weiterarbeiten. Dazu gibt es die Möglichkeit, weitere Tabellen zu definieren, die auf den vorherigen Tabellen basieren. Die Tabellen werden automatisch in der richtigen Reihenfolge und auch asynchron ausgeführt. Alternativ können Sie anstelle von spark den Befehl dlt.read für diesen Zweck verwenden. Dieser Befehl liest die Tabelle aus dem Delta Lake und gibt sie als Datenrahmen zurück.
@dlt.table
def clean_table():
return (
dlt.read("raw_table")
.select("sp1", "sp2")
.withColumn("col3", F.col("col1") + F.col("col2"))
)
Auf die gleiche Weise können Sie die saubere oder goldene Ebene definieren. Natürlich können Sie auch mehrere Tabellen aus den vorherigen Schritten zusammenführen. Das Schöne daran ist, dass solche Zusammenführungen auch im generierten Graphen angezeigt werden.
@dlt.table
def gold_table():
return (
dlt.read("saubere_tabelle")
.join(dlt.read("andere_tabelle"), "id")
)
Datenqualität
Eine weitere Möglichkeit, die eine DLT-Pipeline-Definition bietet, ist die Definition von Datenqualitätstests. Diese können sich auf einzelne Spalten beziehen. Der Mechanismus kann in drei Varianten genutzt werden:
- expect: erwartet, dass eine bestimmte Bedingung erfüllt ist. Andernfalls werden Fehlerstatistiken gesammelt und im Pipeline-Diagramm angezeigt.
- expect_or_fail: Erwartet, dass eine bestimmte Bedingung erfüllt ist. Andernfalls werden die Tabelle und alle auf ihr basierenden Tabellen abgebrochen.
- expect_or_drop: Erwartet eine bestimmte Bedingung, die erfüllt sein muss. Andernfalls werden falsche Werte aus der Tabelle entfernt. Sie wird jedoch nicht abgebrochen.
@dlt.expect_or_fail("name IST NICHT NULL")
@dlt.table
def gold_table():
return (
dlt.read("saubere_tabelle")
.join(dlt.read("andere_tabelle"), "id")
.withColumnRenamed("name", "vorname")
)
Konfiguration
Auch wenn die Pipeline-Definition im Code geschrieben ist, ist es dennoch notwendig, die Pipeline in eine Art Container zu packen. Delta Live Tables bietet hierfür eine Konfiguration, die bei der Erstellung einer Pipeline definiert werden kann.
Sie enthält die Konfiguration des Clusters und den Modus, in dem die Pipeline gestartet wird. Sie können zum Beispiel in einem Entwicklungsmodus arbeiten, in dem der Cluster für längere Zeit eingeschaltet bleibt. Im Produktionsmodus, in dem die Pipeline nur einmal ausgeführt werden soll, wird der Cluster nach der Ausführung wieder heruntergefahren.
Hier kann die Version von Delta Live Tables ausgewählt werden, d.h. die Funktionen, die benötigt werden. Beispielsweise können Datenqualitätstests nur in der erweiterten Version verwendet werden.
Natürlich müssen Sie auch die zu verwendende Pipeline-Definition und die Datenbank, in der die Daten gespeichert werden sollen, angeben.
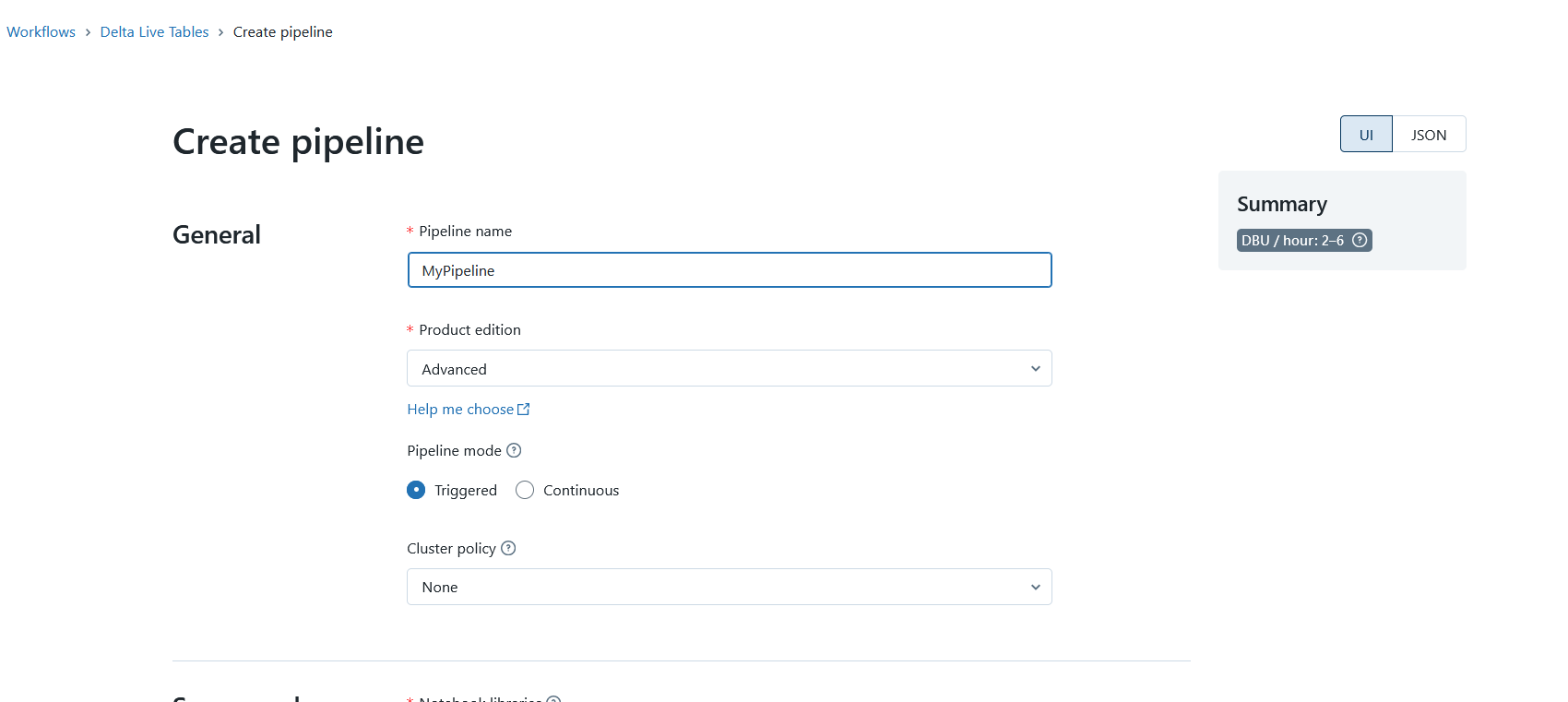 Erstellen einer DLT-Pipeline, Bildquelle: Fabian Stadler
Erstellen einer DLT-Pipeline, Bildquelle: Fabian Stadler
Das bedeutet, dass eine Pipeline-Definition auch in mehreren Konfigurationen/Pipelines verwendet werden kann. Dies ist nützlich, wenn ich mehrere Entwicklungs- und Produktionsumgebungen habe. Das Gleiche gilt für die Wahl der Datenbank. Obwohl ich eine DLT-Pipeline nicht mit Argumenten aufrufen kann, ist es dennoch möglich, bestimmte Dinge in meinem Code in der Konfiguration über Spark-Parameter anders zu machen. Zum Beispiel kann ich unterschiedliche Dateipfade für Konfigurationsdateien angeben. Oder ich kann bestimmte Flags setzen, die meine Pipeline an verschiedenen Stellen verändern.
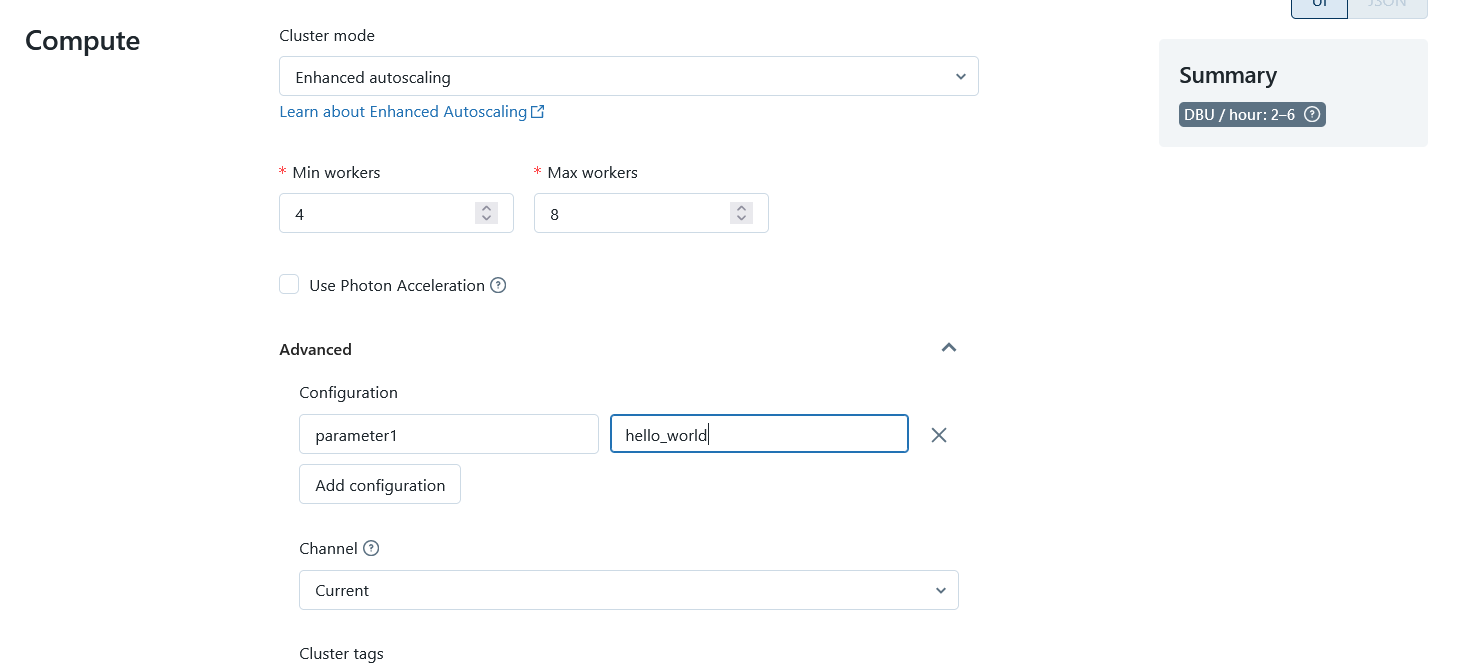 Konfigurieren Sie den DLT-Cluster, Bildquelle: Fabian Stadler_
Konfigurieren Sie den DLT-Cluster, Bildquelle: Fabian Stadler_
Ausführung
Nach dem Konfigurieren und Schreiben einer Pipeline ist die Ausführung mit einem Klick auf eine Schaltfläche einfach. Es ist auch möglich, einen Zeitplan zu definieren oder die Pipeline über die API zu starten.
Im Produktionsmodus wird bei Fehlern, die DLT als vorübergehend betrachtet, automatisch ein erneuter Versuch gestartet. Dies kann zum Beispiel bei Netzwerkproblemen der Fall sein. Dies funktioniert jedoch nicht immer reibungslos, was oft zu unnötigen Wiederholungsversuchen führt.
Visualisierung
Die Visualisierung der Datenpipeline erfolgt über sogenannte DAGs (Directed Acyclic Graphs). Diese ähneln den grafischen Oberflächen von Low-Code-Plattformen, haben aber einige Vorteile. Zum einen sind sie in der Regel einfacher zu lesen und zu verstehen. Zum anderen können sie mit einem Code-Editor geöffnet und bearbeitet werden. Die meisten Low-Code-Plattformen bieten diese Möglichkeit nicht. Stattdessen arbeiten sie mit Formaten wie JSON, XMl oder YAML mit ihrer eigenen Syntax.
Dies bringt Delta Live Tables mit direkter Unterstützung für Data Lineage. Da die einzelnen Stufen Datentransformationen beschreiben, ist auch direkt ersichtlich, welche Daten woher kommen und wohin sie gehen. Dies ist ein wesentlicher Vorteil gegenüber Low-Code-Plattformen, die hierfür eigene Werkzeuge anbieten.
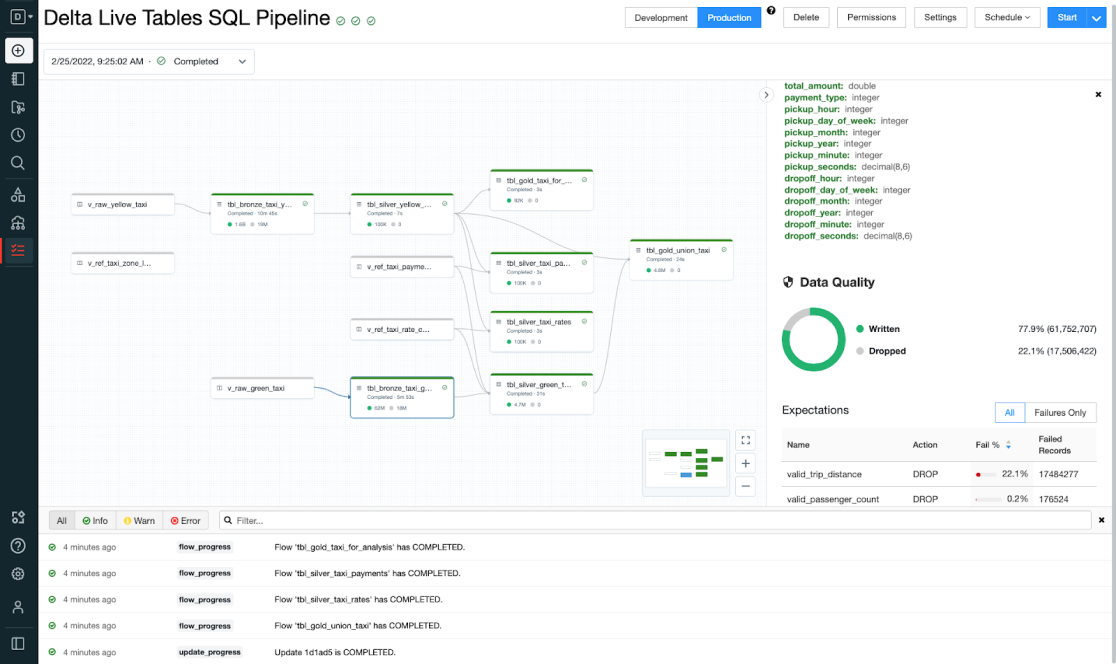 Die Benutzeroberfläche von Delta Live Tables, Bildquelle: Databricks
Die Benutzeroberfläche von Delta Live Tables, Bildquelle: Databricks
Darüber hinaus kann die Anzeige der DAGs auch einzelne Pipelinestrings nachladen. Dies vereinfacht die Handhabung erheblich.
Wie bereits erwähnt, können Sie auch Informationen zur Datenqualität direkt in den Graphen einsehen. Dies ist mit einem Klick auf die entsprechende Stufe möglich und wird in einer schönen Seitenleiste angezeigt. Wenn Sie noch mehr Visualisierung machen wollen und auch eine längere Zeitreihe von Datenqualitätstests auswerten wollen, können Sie dies über Databricks SQL mit einem Dashboard tun. Da die Log-Informationen in Deltatabellen gespeichert werden, können sie direkt über SQL abgefragt und visualisiert werden.
Fazit
Nachdem ich Ihnen nun viel über Delta Live Tables erzählt habe, möchte ich ein Fazit ziehen. Natürlich habe ich viele Dinge nur angerissen, aber es gibt noch viele weitere Funktionen, die in der Dokumentation zu finden sind. Aber aus meiner Arbeit mit dem Framework kann ich sagen, dass es viele Dinge vereinfacht und die Arbeit mit Datenpipelines viel angenehmer macht, als sie komplett in Code zu schreiben. Insbesondere die Orchestrierung ist extrem einfach und mit nur wenigen Zeilen Code möglich.
Die Visualisierung der Datenpipeline ist ebenfalls sehr gut gelungen und bietet viele Möglichkeiten zur Überwachung der Datenqualität. Wenn man nicht bereits eine entsprechende Lösung hat, ist DLT eine geeignete Alternative.
Allerdings ist es auch so, dass man etwas abhängig von der Plattform wird - viel mehr, als es bisher bei Databricks der Fall war. Das liegt daran, dass die Cluster nur in gemanagter Form verfügbar sind. Auch für den Code gibt es nur das Notebook mit dem dlt-Paket als einzige Nutzungsmöglichkeit. Der Weg zurück zu Python oder in eine Low-Code-Alternative ist also nicht mehr so einfach.
Außerdem ist Databricks selbst schon deutlich teurer als z.B. Azure Mapping Dataflows oder Azure Synapse Notebooks. Mit DLT wird es noch teurer, und wenn man Datenqualitätstests verwenden möchte, wird es noch teurer. Bei sehr langen Pipelines, die täglich ausgeführt werden, kann es also eine gute Idee sein, doch auf High Code zu setzen und die Pipeline auf einem kostengünstigen Job-Cluster auszuführen.
Schließlich bleibt noch zu sagen, dass DLT nicht unbedingt für externe Extraktionsprozesse geeignet ist. Hier ist es besser, auf separate Jobs zu setzen oder Konnektoren zu nutzen, wie sie in Low-Code-Plattformen wie Azure Data Factory oder AWS Glue angeboten werden. Ich habe DLT eher für die Datenintegration innerhalb eines Data Lake gedacht. Das bedeutet, dass Sie in der Realität mehrere Lösungen haben, die mehr oder weniger gut zusammenarbeiten.
DLT ist also eine hervorragende Lösung, wenn man sich komplett auf Databricks verlässt und sich von ihnen abhängig machen kann oder will. Als Self-Service-Lösung mit Databricks SQL und Databricks ML vereinfacht sie die Arbeit mit Datenpipelines erheblich.
Wer sich jedoch nicht binden möchte und die hohen Kosten sowie den weiteren Overhead fürchtet, für den ist Delta Live Tables vielleicht nicht die richtige Lösung. Letztendlich hängt es wie immer von den individuellen Anforderungen ab, ob sich ein neues Framework wie DLT lohnt oder nicht.

