
In den letzten Jahren hat sich die Data-Lake-Architektur zum De-facto-Standard für Big-Data-Anwendungsfälle entwickelt. Allerdings haben viele Unternehmen ihre Datenschicht für BI-Anwendungsfälle immer noch auf relationalen Datenbanken aufgebaut. Dies war auch bei einem meiner früheren Projekte der Fall. Dort hatten wir ein Data Warehouse für BI-Anwendungsfälle und einen Data Lake für Data Scientists.
Um diese Redundanz zu überwinden, wollten wir auf die Data Lakehouse-Architektur umsteigen, die genau zur Lösung dieser Probleme entwickelt wurde. Dieser neue Ansatz für das Data Engineering vereint Data Lake und Data Warehouse und behebt die Unzulänglichkeiten der Data Lake-Architektur.
Delta Lake
In diesem speziellen Projekt haben wir hauptsächlich mit Azure Data Factory und Azure Databricks gearbeitet. Eines der wichtigsten Verkaufsargumente von Databricks ist die hervorragende Unterstützung für Delta Lake. Diese Open-Source-Architektur basiert im Gegensatz zu Datenbankmanagementsystemen auf bloßen Dateien, genauer gesagt auf Deltatabellen.
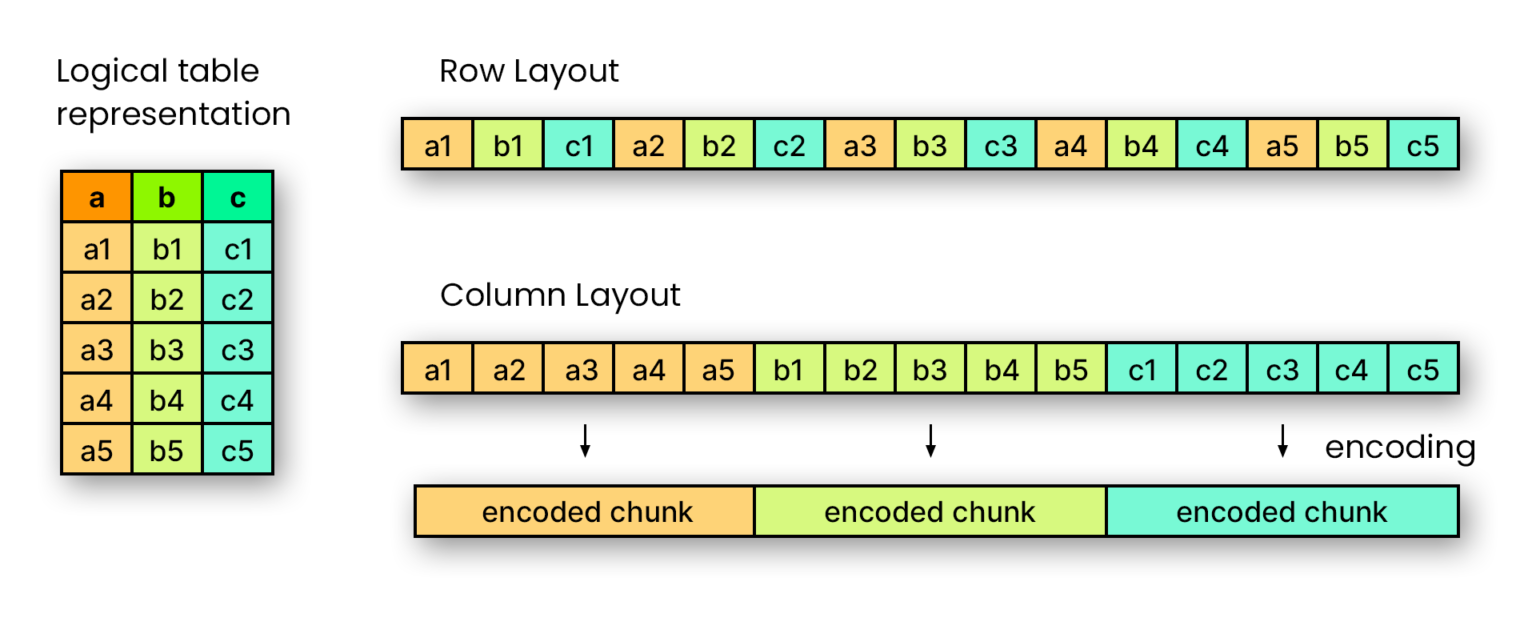
Deltatabellen erweitern zunächst das populäre Dateiformat Apache Parquet. Dabei handelt es sich wiederum um ein spaltenorientiertes Dateiformat, das für die effiziente Speicherung und den Abruf von Daten konzipiert wurde. Man kann sich das so vorstellen: In einer Parquet-Datei wird jede Spalte als zusammenhängende Einheit gespeichert, eine nach der anderen. Dies steht im Gegensatz zu zeilenbasierten Formaten, wie CSV oder JSON.
 Zeilenbasierte vs. spaltenbasierte Darstellung, Bildquelle: Dremio
Zeilenbasierte vs. spaltenbasierte Darstellung, Bildquelle: Dremio
Genauer gesagt, ist eine Parquet-Datei in so genannte Row Groups unterteilt. Diese stellen eine logische, horizontale Partitionierung der Daten in Zeilen dar. Jede Row Group enthält einen Column Chunk, d.h. einen Teil der Daten für eine bestimmte Spalte. Dieser ist garantiert zusammenhängend, was das Lesen von Datensätzen mit deutlich mehr Zeilen als Spalten vereinfacht. Zuletzt werden die Column Chunks noch einmal in mehrere Pages unterteilt, die hinsichtlich Kompression und Kodierung unteilbar sind.
Apache Parquet wurde in Zusammenarbeit entwickelt 2013 von Twitter und Cloudera als Open-Source-Format veröffentlicht, das unabhängig von jeder Programmiersprache ist. Ziel war die Entwicklung einer modernen spaltenbasierten Speicherebene, die von bestehenden Hadoop-Frameworks verwendet werden kann.
Da alle Werte in einer bestimmten Spalte denselben Typ haben, funktioniert die Komprimierung besser, und wir können sie typspezifisch anwenden. Außerdem werden die Spaltenwerte fortlaufend gespeichert, so dass eine Abfrage-Engine das Laden nicht benötigter Spalten überspringen kann. Dies macht das Parquet-Format sehr effizient für OLAP-Anwendungen (Online Analytical Processing), bei denen eine schnelle Antwort auf multidimensionale analytische Abfragen gewährleistet sein muss.
Damit einher geht jedoch auch eine Schwäche des Parquet-Formats: Aufgrund seines spaltenorientierten Speicheransatzes ist Apache Parquet nicht sehr gut für Dateneinfügungs- und -löschtransaktionen geeignet. Idealerweise fügt man nur neue Daten hinzu, ohne den bestehenden Datensatz zu verändern. Dies gilt auch für das Aktualisieren bestehender Daten. Manchmal ist es auch wünschenswert, verschiedene Versionen des Datensatzes zu speichern, damit man im Notfall alte Bestände wiederherstellen kann.
Um diese Probleme zu lösen, wurde das Open-Source-Projekt Delta Lake ins Leben gerufen. Delta Lake bietet ACID-Transaktionen, skalierbare Metadatenverarbeitung und vereinheitlicht die Streaming- und Batch-Datenverarbeitung auf bestehenden Data Lakes wie S3, ADLS, GCS und HDFS.
Dies wird durch serialisierbare Isolationsebenen gewährleistet, die verhindern, dass Leser inkonsistente Daten sehen. Darüber hinaus wird die verteilte Verarbeitungsleistung von Spark genutzt, um alle Metadaten für Tabellen im Petabyte-Bereich mit Milliarden von Dateien zu verarbeiten. Eine Tabelle in Delta Lake ist sowohl eine Stapeltabelle als auch eine Streaming-Quelle und -Senke. Streaming Data Ingest, Batch Historical Backfill, interaktive Abfragen - alles funktioniert out-of-the-box.
Schemaabweichungen werden automatisch behandelt, um das Einfügen fehlerhafter Datensätze während der Aufnahme zu verhindern. Und die integrierte Datenversionierung ermöglicht Rollbacks, vollständige historische Prüfpfade und reproduzierbare Experimente zum maschinellen Lernen. Letztendlich werden sogar Zusammenführungs-, Aktualisierungs- und Löschvorgänge unterstützt, um komplexe Anwendungsfälle wie die Erfassung von Änderungsdaten, SCD-Vorgänge (Slowly Changing Dimensions), Streaming-Upserts usw. zu ermöglichen.
Kosten der Speicherung vs. Kosten der Verarbeitung
In den letzten Jahrzehnten hat sich die Datenverarbeitung aufgrund von Infrastrukturentwicklungen stark verändert. Grob gesagt, wurden die Kosten für die Datenspeicherung immer geringer, während die zu verarbeitende Datenmenge immer größer wurde.
Bisherige Architekturen wie Data Warehouses können diese oft unstrukturierten oder halbstrukturierten Datenmengen nicht mehr bewältigen und sind entsprechend teuer in Betrieb und Wartung sowie in der Integration. Aus diesem Grund ist es eine logische Entwicklung, auf eine Architektur zu setzen, die kostengünstigen Cloud-Speicher nutzt, nämlich einen Data Lake.
Für gängige OLAP-Anwendungsfälle ist es sinnvoll, den oben erwähnten Delta Lake mit einem Data Lake zu kombinieren, um Daten in Dateien statt in relationalen Datenbanken zu speichern. Das Problem dabei ist jedoch, dass ich nun mehrere andere Komponenten für mein Infrastrukturmanagement benötige.
Zum einen brauche ich Ressourcen, die meine Daten aus verschiedenen anderen Systemen in meinen Data Lake integrieren. Andererseits muss ich meinen Datennutzern eine Möglichkeit bieten, die Daten, die sie verarbeiten wollen, herunterzuladen.
Aus diesem Grund haben viele Unternehmen in der Vergangenheit eigenartige hybride Systeme entwickelt, bei denen sie alle Arten von Daten in einem Data Lake speichern, aber Teile davon über einen ETL-Prozess (Extract, Transform, Load) in strukturierte Berichte in Data Warehouses übertragen.
Unstrukturierte Daten werden den Nutzern direkt in unstrukturiertem Format über eine Cloud-API zur Verfügung gestellt, während strukturierte Daten über das Data Warehouse bereitgestellt werden. Die Folge: doppelte Rechteverwaltung, redundante ETL-Workflows, mehrfache Datenübertragungen, Unterschiede zwischen gespeicherten und produktiven Daten und so weiter und so fort.
Data Lakehouse - eine Erweiterung
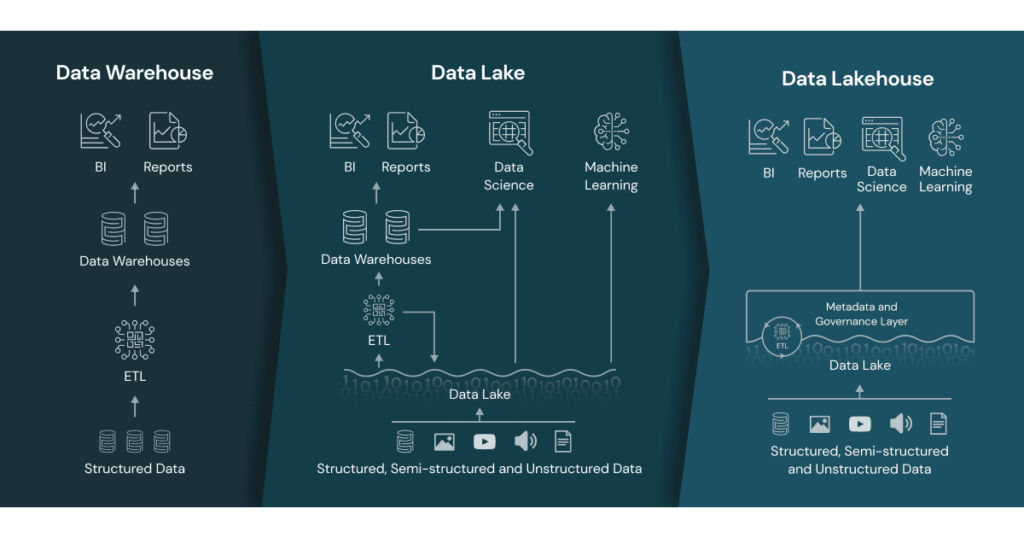
Um diese Ansätze zu vereinheitlichen, wurde das Konzept des Data Lakehouse entwickelt. Dieses Konzept baut auf den oben genannten Ansätzen auf und vereinheitlicht redundante Operationen, indem es alles im Data Lake stattfinden lässt.
Anstatt Spark-Cluster oder andere Server nur für die Umwandlung unstrukturierter Daten in strukturierte Daten zu verwenden, wie es bei Databricks seit langem der Fall ist, werden Spark-Cluster nun zum öffentlichen Endpunkt für das Herunterladen von Daten.
Der größte Teil der Daten wird in Deltatabellen auf billigem Speicher in der Cloud gespeichert. Doch anders als in einem traditionellen Data Lake wird der Zugriff durch eine neue Metadatenschicht geregelt, die alle Objekte in Datenkatalogen verwaltet. Dazu gehören auch das Rechtemanagement sowie weitere Informationen zur Datenherkunft für die Datenabfolge.
 Das Data Lakehouse bietet rohe und kuratierte Daten, Bildquelle: Databricks
Das Data Lakehouse bietet rohe und kuratierte Daten, Bildquelle: Databricks
Die Metadatenschicht fungiert als eine einzige Quelle der Wahrheit für alle Daten. Dies ist ein enormer Vorteil, denn so können Sie alle Daten an einem Ort und nicht in verschiedenen Systemen verwalten. Sie können externe Tabellen in verschiedenen Formaten hinzufügen, z. B. CSV, JSON, Parquet und so weiter. Darüber hinaus werden Ihre kuratierten Daten in produktionsreifen Deltatabellen gespeichert, die für analytische Arbeitslasten optimiert sind. Es ist sogar möglich, Tabellen von anderen Cloud-Anbietern hinzuzufügen, während Ihre Metadatenschicht als einziger Einstiegspunkt dient.
Auf diese Weise können Sie Ihren Endnutzern eine einzige Schnittstelle für Rohdaten und kuratierte Daten anbieten, anstatt wie bisher zwei getrennte Systeme zu unterhalten. Datenanalysten können auf ihre Rohdaten auf dieselbe Weise zugreifen wie Geschäftsanwender auf kuratierte Daten. Die Unterstützung von programmatischen APIs, wie sie Spark bietet, macht es für Entwickler besonders einfach, die benötigten Daten aufzunehmen.
Wie die Serving-Schicht arbeitet auch die Verarbeitungsschicht auf kostengünstigen Spark-Clustern, die auf derselben Plattform verwaltet werden können. Das bedeutet, dass Sie dieselbe Infrastruktur verwenden können, z. B. einen selbst verwalteten Kubernetes-Cluster oder Databricks als Analyseplattform, die all diese Ideen kombiniert. Alles, was vorher separate Lösungen brauchte, kommt an einem Ort zusammen.
Fazit
Das Data Lakehouse vervollständigt sozusagen die Idee des Delta Lake und macht den Einsatz von Data Warehouses vorerst obsolet. Man könnte sogar sagen, dass das Data Lakehouse ein Data Warehouse darstellt, nur mit quelloffenen, leicht zugänglichen Formaten, kostengünstiger Speicherung und hochperformanter On-Demand-Verarbeitung als Basis.
Es bietet eine einzige Quelle der Wahrheit für alle Daten und damit einen einzigen Verwaltungspunkt. Plattformen können darauf aufbauen, so dass eine redundante Infrastruktur nicht mehr erforderlich ist. Dadurch werden die Kosten für das Infrastrukturmanagement gesenkt und die Unternehmen können sich auf ihre Daten konzentrieren.
Bei der Arbeit mit der Architektur habe ich festgestellt, dass das Potenzial riesig ist und dass das Data Lakehouse ein vielversprechendes Konzept ist. Es ist eine logische Weiterentwicklung des Data Lakes und eine großartige Möglichkeit, Daten für alle Benutzer auf einfache und effiziente Weise verfügbar zu machen. Vor allem in großen Unternehmen bin ich davon überzeugt, dass die digitale Transformation durch das Data Lakehouse beschleunigt werden wird.

