Labelling Project Tickets with Mistral Embed API
Published on August 26, 2024 by Fabian Stadler
Most people will by now have used ChatGPT or some other kind of AI to generate text, answer questions, or roleplay. But a lesser known capability of these large language models (LLMs) is the creation of embeddings. These numerical representations of text can be used for a variety of tasks, such as clustering, classification or similarity search.
In this case study, I explore the capibility of embeddings in regard of ticket systems. I will demonstrate how you can use an embedding model to label tickets from any project and how you can reduce manual labour in project management, software development, or customer support.
What are embeddings?
To put it very briefly, embeddings are a huge vectors that represent semantic meaning of text. For non-mathematicians, this means that similar text will produce similar sets of numbers.
Let's say you have a text that says 'The quick brown fox jumps over the lazy dog' and another text that says 'The fast brown fox jumps over the lazy dog'. Using a distance measure like the euclidean distance, the difference of both embeddings will be very small. This is because the only difference is the word 'quick' and 'fast', which are very similar in meaning.
As you might already expect, this makes embeddings very useful to compare text. Use cases can be found in search engines, plagiarism detection, recommendation systems and many more.
If you're very new to this topic, I recommend reading Mistral AI's guide on classifying disease symptoms first.
Using embeddings to label tickets
In their initial example, Mistral AI shows how you can use a dataset with one column describing disease symptoms and another column describing the disease to create a logistic regression model based on embeddings. This can then be used to classify new symptom descriptions by humans to give a hint on the disease.
In software development, customer support or logistics, you mainly have to deal with human descriptions either -- in form of tickets. These can be bug reports, feature requests, complaints or even deliveries. In a large project, it can be very time consuming to follow a good concept of labelling and wrong labels might cause delays or even more work. So I wanted to explore how well an embedding model can classify these tickets without any prior knowledge of the project.
Embedding GitHub issues
As a very simple example, I used the GitHub issues of the Ruby language as dataset because it is a fairly large project and the GitHub API makes it very easy to download issues from all projects.
Just call the endpoint https://api.github.com/repos/ruby/ruby/issues and you
will get a list of all open issues including title, body, creation date and
many more that you can then save into a DataFrame or CSV. For the exact code
to get the issues, write them into a CSV and put them into a pandas DataFrame,
I refer to the notebook in my GitHub
project.
After you've collected the issues, you can already use Mistral AI's embedding model to create a column with embeddings in your DataFrame. Luckily, Mistral AI provides a nice Python library. Additionally, their OpenAPI documentation also allows usage in different languages, such as C#, with code generation tools such as NSwagStudio.
from mistralai import Mistral
import ast
def convert_embeddings(embeddings_str):
return ast.literal_eval(embeddings_str)
def get_embeddings_by_chunks(data, chunk_size):
chunks = [data[x : x + chunk_size] for x in range(0, len(data), chunk_size)]
embeddings_response = [
client.embeddings.create(model=model, inputs=c) for c in chunks
]
return [d.embedding for e in embeddings_response for d in e.data]
api_key = os.environ["MISTRAL_API_KEY"]
client = Mistral(api_key=api_key)
if not os.path.exists("github_issues_embedded.csv"):
model = "mistral-embed"
df["embeddings"] = get_embeddings_by_chunks(df["title"].tolist(), 50)
df.to_csv('github_issues_embedded.csv', index=False)
print("Issues embedded successfully.")
else:
df = pd.read_csv('github_issues_embedded.csv')
df['embeddings'] = df['embeddings'].apply(convert_embeddings)
print("Issues already embedded.")
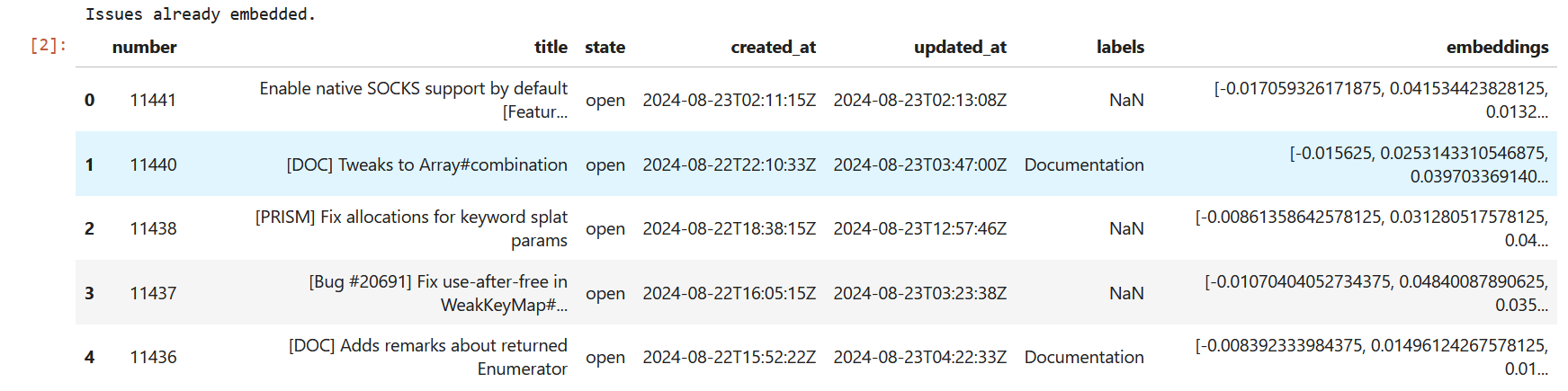
df.head()
For simplicity, I only use the issue title as base for classification. Normally, you would try to embed as much information as possible for better comparison. The Python library also comes with a method to create embeddings in chunks, which is very useful for large datasets. Since we have roughly 420 open issues here, this is a matter of seconds. Our DataFrame now looks like this:
Finding the optimal number of clusters
As I said before, in this case study we have no prior knowledge of the project -- which I really don't have. This means we need a way to group the embedding vectors. A popular method for this is the k-means algorithm.
K-means is a simple algorithm that tries to find k clusters in a dataset. In its simplest form, it works by randomly initializing k centroids and then assigning each data point to the nearest centroid. After that, the centroids are recalculated and the process is repeated until the centroids don't change anymore.
The algorithm works differently depending on the number of clusters you have to set beforehand. In order to find the best number of clusters, you can use the elbow method or calculate the silhouette score. For simplicity, I plotted the average silhouette score up to 50 clusters. You will find this code too in the repository.
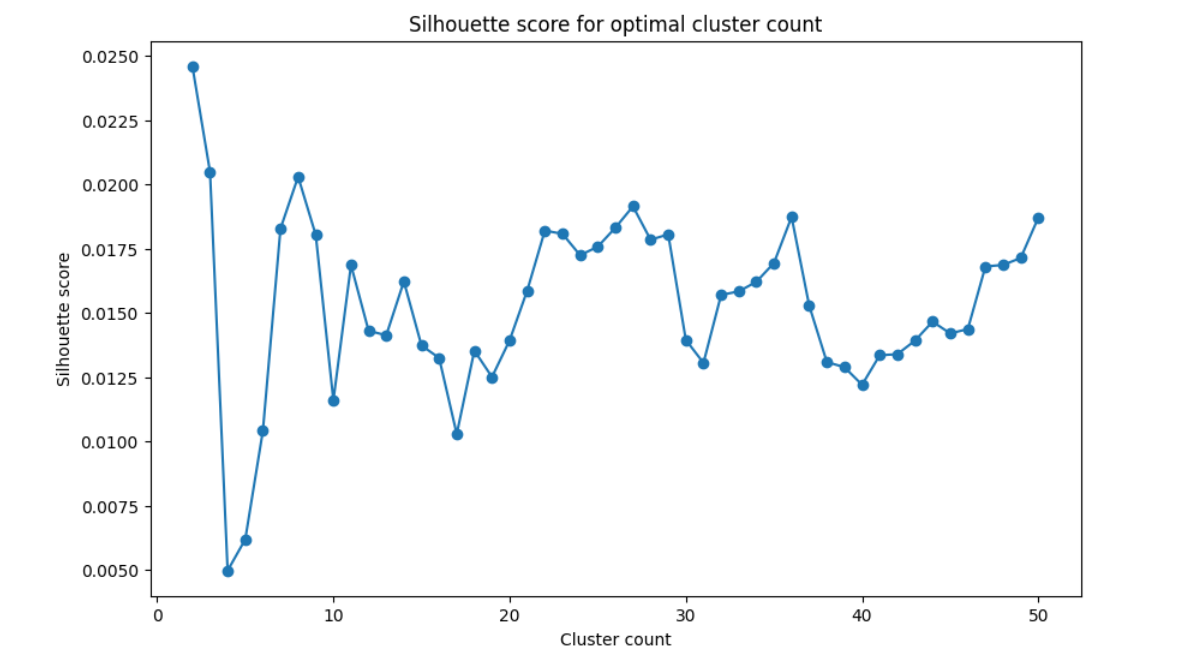
A good score would be above 0.5. But in this project descriptions are very similar and the borders often intersect. Tasks such as optimization, testing, documentation are common in all areas. Choosing a small number will result in very general categories. Calculating the silhouette score for more than 50 clusters gives much better results. Yet we also do not want to have a label for every second issue. I decided to go with 20 clusters as this is the maximum of what can be visualized well.
Clustering with k-means
Using scikit-learn makes it very easy to use the k-means algorithm on our embeddings.
model = KMeans(n_clusters=20, max_iter=1000)
model.fit(df['embeddings'].to_list())
df["cluster"] = model.labels_
As a result you will get a new column with the id of the cluster. You can then use this information to label your tickets. Using seaborn, you can visualize the embeddings.
import seaborn as sns
from sklearn.manifold import TSNE
import numpy as np
tsne = TSNE(n_components=2, random_state=0).fit_transform(np.array(df['embeddings'].to_list()))
ax = sns.scatterplot(x=tsne[:, 0], y=tsne[:, 1], hue=np.array(df['cluster'].to_list()))
sns.move_legend(ax, 'upper left', bbox_to_anchor=(1, 1))
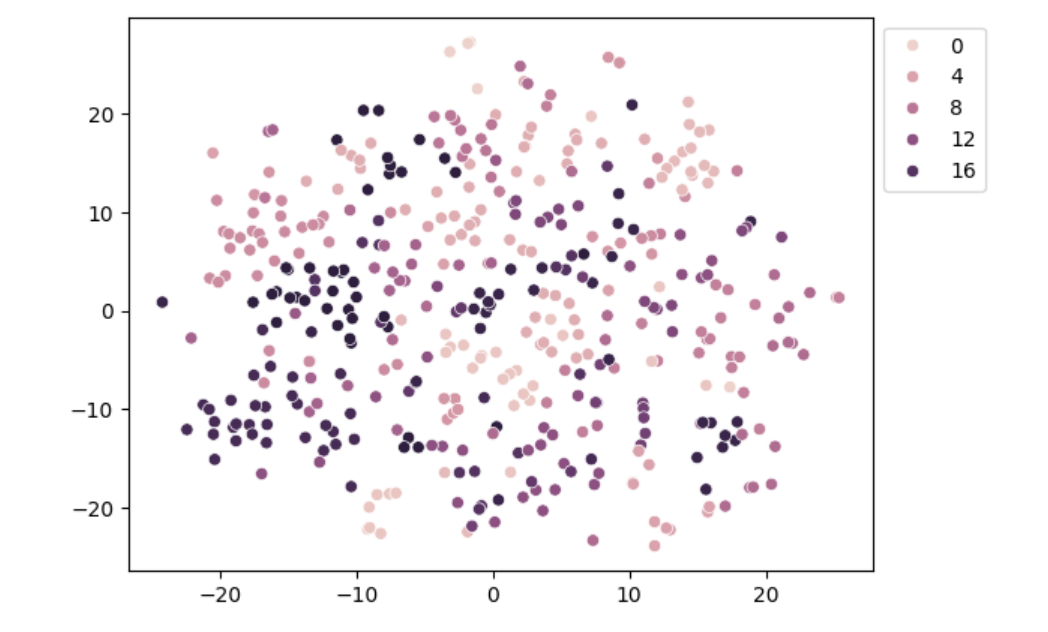
I used the t-SNE algorithm here to reduce the dimensionality of the embeddings to two dimensions. This is because an embedding vector has 1024 dimensions and is impossible to visualize for the human eye. The algorithm tries to keep the distances between the points as close as possible to the original distances. This way we can see which rows are close to each other and which are not.
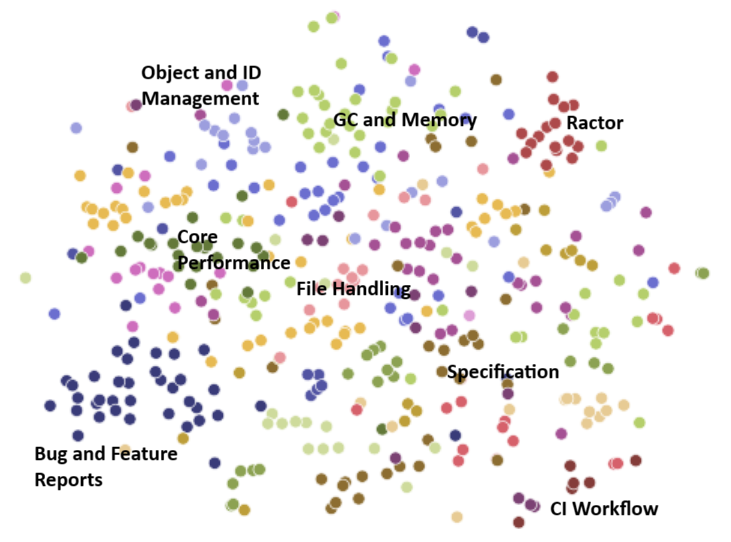
The plot groups some clusters and does not show all 20. You will see those at the end of this article.
Creating labels for the clusters
So now we have 20 clusters and we can see which tickets are close to each other. But we still don't really know the common topic. We know the titles though to give us a hint.
Using a random set of samples from each cluster, we can send a prompt to a Mistral AI's large model. This one is the best for complex tasks and since we need to do this only once, the cost will be very low.
def select_representative_titles(df, num_titles=20):
cluster_titles = {}
for cluster in df['cluster'].unique():
cluster_df = df[df['cluster'] == cluster]
representative_titles = cluster_df['title'].sample(min(num_titles, len(cluster_df)), random_state=42).tolist()
cluster_titles[cluster] = representative_titles
return cluster_titles
def generate_category_label(titles):
prompt = f"""
Please generate a category name for the following list of titles:
{', '.join(titles)}
The category should show common attributes or topics of the titles but be very specific.
You must not use general terms like optimization, improvements, fixes, enhancements in the category name.
Only print the category name and do not include special characters.
"""
chat_response = client.chat.complete(
model = "mistral-large-latest",
messages = [
{
"role": "user",
"content": prompt
},
]
)
return chat_response.choices[0].message.content
def generate_cluster_labels(representative_titles):
cluster_labels = {}
for cluster, titles in representative_titles.items():
label = generate_category_label(titles)
cluster_labels[cluster] = label
return cluster_labels
if not os.path.exists('github_issues_embedded_and_labeled.csv'):
representative_titles = select_representative_titles(df)
cluster_labels = generate_cluster_labels(representative_titles)
df['cluster_label'] = df['cluster'].map(cluster_labels)
df.to_csv('github_issues_embedded_and_labeled.csv', index=False)
print("Issues labeled successfully.")
else:
df = pd.read_csv('github_issues_embedded_and_labeled.csv')
df['embeddings'] = df['embeddings'].apply(convert_embeddings)
print("Issues already labeled.")
df.head()[["title", "cluster_label"]]
The above code will get a list of 20 representative titles, send them in a prompt to Mistral AI and receive a label for each cluster. You might notice that I tried in my prompt to avoid general terms like 'optimization', 'improvements', 'fixes' or 'enhancements'. Yet, the AI will still come up with these general terms sometimes. I also want to avoid special characters in the label since we do not want those. In production you will might want to adjust the prompt to your needs.
As a result, we now have labels for our clusters and can finally produce a useful visualization.
tsne = TSNE(n_components=2, random_state=0).fit_transform(np.array(df['embeddings'].to_list()))
ax = sns.scatterplot(x=tsne[:, 0], y=tsne[:, 1], hue=np.array(df['cluster_label'].to_list()), palette='tab20b')
sns.move_legend(ax, 'upper left', bbox_to_anchor=(1, 1))
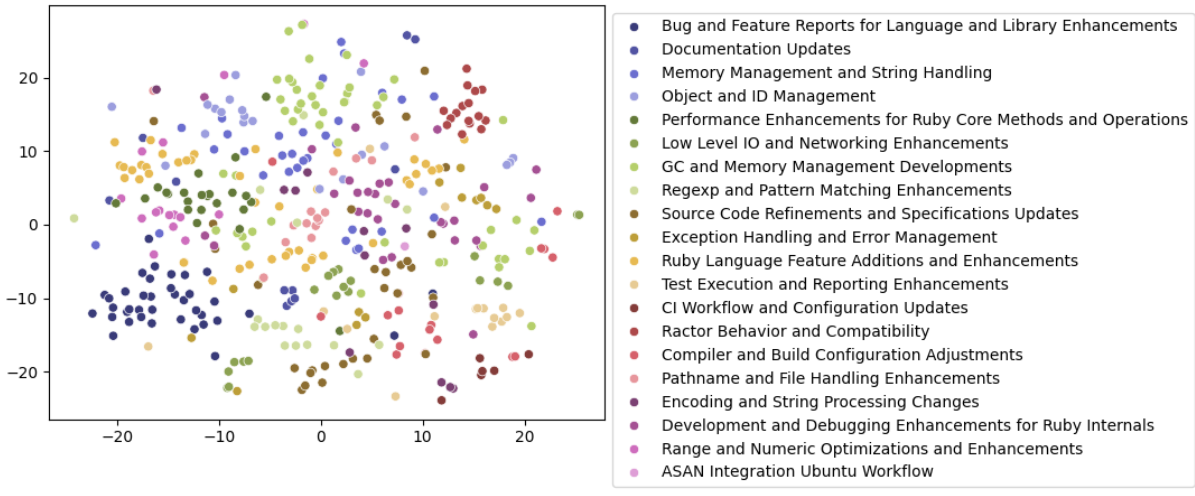
Although there are many outliers, you can see distinct clusters. Printing some of them shows that the issues seem to be grouped fairly well. For a good evaluation, you would need to do a thorough check and set a measure to quantify the quality.
pd.set_option('display.max_colwidth', 1000)
df[df['cluster_label'] == 'Bug and Feature Reports for Language and Library Enhancements'].title.head(10)

Final thoughts
Using Mistral Embed API to classify tickets is a very promising approach that I set up in maybe an hour. The model cost for tinkering was a few cents and the result is acceptable.
For a real world scenario I see a lot of use cases such as classifying customer support requests, complaints or user content. Most ticket systems provide easy to use APIs for exporting data. With Mistral AI or some other embedding model, you can easily classify these and create fully automated labelling bots.
Of course this experiment still has much room for improvement. By using more context information, fine-tuning prompts and distance measures, I expect even better results. But it is a good start to explore possible categories.
For future classification, you can train a logistic regression model as shown in the Mistral AI guide. Since the embedding model currently only costs about 10ct for a million tokens (which is about 4 million characters in English), cost is reduced by more than 50% in comparison to using Mistral AI's open- source model Nemo (27ct/1mio. tokens) with a prompt specifying predefined categories. This makes the approach very cost-effective and fast due to the support of batch processing.
If you have any questions or feedback, feel free to write me a mail or reach out to me on any of my social media channels.